
Web Scraping vs API: Which Data Extraction Method Should You Choose?

You’re staring at a website full of data you need. The question isn’t whether you can get it—it’s how. Should you build a scraper or integrate an API? Both work, but they solve different problems. Understanding the distinction between them saves time, money, and engineering headaches.
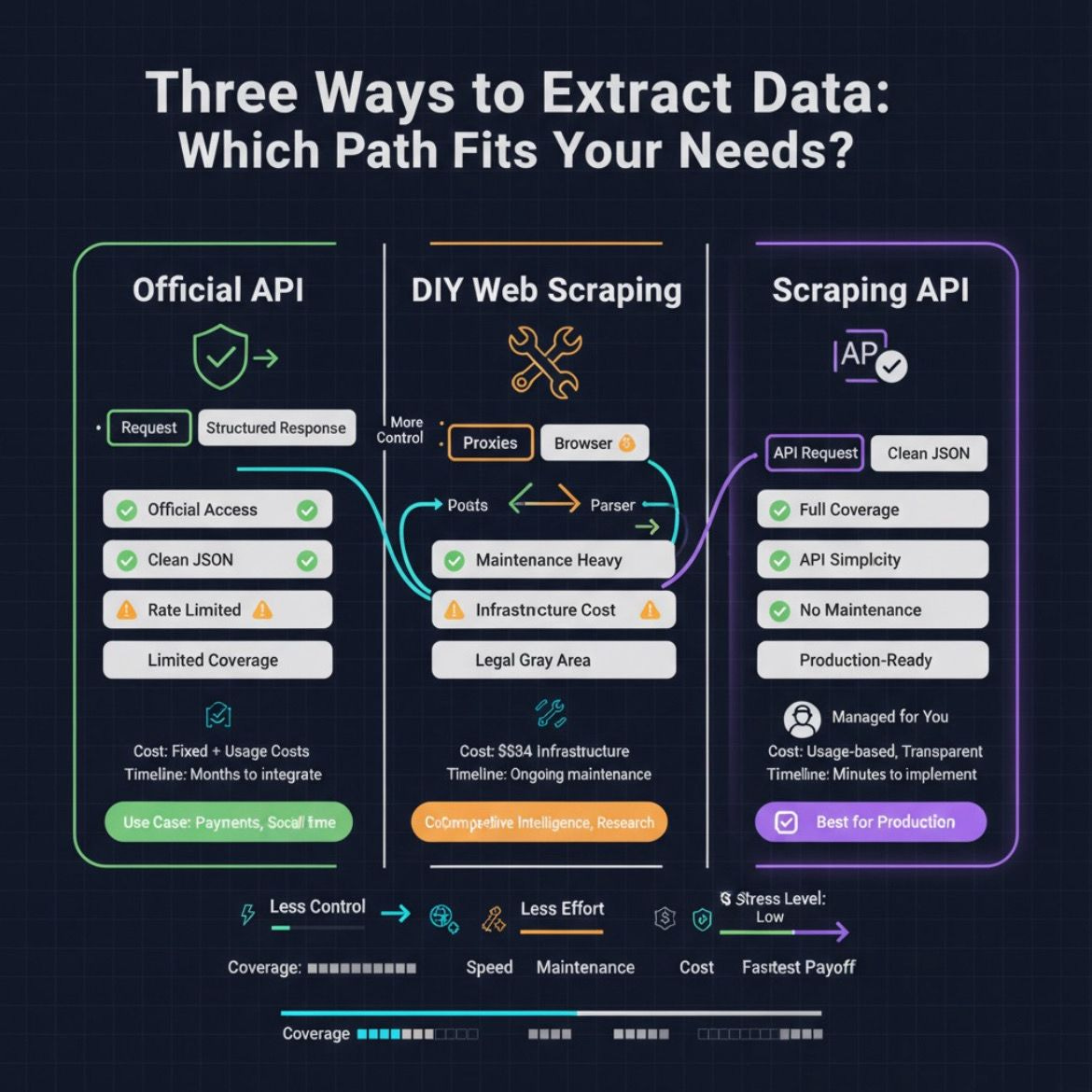
APIs: Clean Data, Official Access
An API is like having an authorized waiter bring you exactly what you ordered. Providers deliver structured data through official channels in predictable JSON or XML formats. You get authentication, rate limits, version control, and—crucially—legal permission to access the data.
When APIs shine: Payment systems (Stripe, PayPal), real-time data (financial feeds, social media), and compliance-sensitive applications. Twitter/X and LinkedIn provide authenticated APIs with clear terms of service. This matters for production systems where reliability and legal standing are non-negotiable.
The limitation: APIs only expose what providers allow. Missing a critical data field? Too bad—it’s not available through their endpoints. Many websites don’t offer APIs at all, leaving you without official access.
Web Scraping: Unlimited Coverage, Higher Maintenance
Web scraping is different. You visit websites, parse their HTML, and extract whatever you can see in your browser. If it’s visible on the page, you can scrape it.
When scraping wins: E-commerce price tracking across retailers that lack product APIs, SERP monitoring for SEO research, news aggregation from niche sources, extracting product reviews or stock status that APIs don’t expose. Scraping fills gaps where official access doesn’t exist.
The cost: You manage proxies, handle anti-bot defenses, deal with JavaScript rendering, and maintain extraction logic. A website redesign breaks your scraper. It’s flexible but demands ongoing engineering attention.
The Real Numbers: Cost Comparison
Building custom scrapers requires infrastructure investment—servers, proxies, browser automation tools, and developer time. APIs flip this model with usage-based pricing: you pay per request or data volume.
For small volumes (under 10,000 requests monthly), scraping infrastructure likely costs more. At high volumes (100,000+ requests), scraping’s unlimited access becomes economical. The breakeven varies, but most teams find it around 10,000-50,000 monthly requests depending on complexity.
Hybrid Pipelines: The Best of Both
Smart data teams use both methods strategically. Start with APIs for reliable core data from major providers. Supplement with scraping for missing fields or smaller competitors that lack official APIs. Normalize everything to one schema so downstream applications ignore the source.
Example: E-commerce intelligence requires tracking competitor prices across retailers. Use Amazon’s API for their data. Scrape smaller retailers’ product pages for completeness. Merge into one dataset.
This approach balances reliability (APIs) with coverage (scraping).
Making Your Decision: Five Questions
1) Is there an official API? Start there if available.
2) Does it include everything you need? If the API lacks fields, you’ll need scraping anyway.
3) Do rate limits match your volume? High-frequency data needs might require scraping’s parallelization.
4) What are compliance requirements? Sensitive data and regulated industries need official access.
5) Can you afford API fees or ongoing maintenance? Budget constraints influence the choice.
The Modern Solution: Scraping APIs
Web scraping APIs offer a third path—they handle all technical complexity while delivering API simplicity. You send requests specifying target URLs and extraction requirements. The service manages proxies, anti-bot measures, JavaScript rendering, and CAPTCHA solving. You get clean JSON responses without maintaining infrastructure.
This approach works for production systems needing reliable data from multiple sources without engineering overhead
.
Compliance Matters
Web scraping operates in a grayer legal zone than APIs. Respect robots.txt files, honor website terms of service, and comply with data privacy regulations. Scraping is generally legal for publicly visible data, but commercial applications benefit from legal review. APIs provide explicit permission and clear audit trails.
Final Decision Framework
Choose APIs for official data, compliance-critical applications, and real-time updates.
Choose web scraping for comprehensive coverage, competitive intelligence, and non-API sources.
Choose scraping APIs for production systems needing both flexibility and reliability.
The best approach depends on your specific data needs, budget, and maintenance capacity. Most successful data projects combine these methods strategically—using official APIs where they work, supplementing with scraping where they don’t.